




Diese Technologie ist auch der Auslöser der zweiten industriellen Revolution. Erweiterte die Erfindung von Maschinen die physischen Fähigkeiten der Menschen, so wirkt sich die zweite industrielle Revolution auf die geistigen Fähigkeiten der Menschen aus. Immer mehr Maschinen werden konstruiert, die - wie wir Menschen selbst - mit Daten, Information und Wissen hantieren.
Die ersten Revolution wurde angetrieben durch das Angebot natürlicher Ressourcen und die Nachfrage nach aus ihnen hergestellten Produkten, welche von Menschen alleine mit Muskelkraft nicht mehr in ausreichendem Maße befriedigt werden konnte. Heute ist es die Menge an Wissen und der Wunsch, diese in handlungsrelevante Information umzuwandeln, welches die Maschinen der zweiten industriellen Revolution vorantreibt. Menschen sind durch ihre begrenzten kognitiven Fähigkeiten, welche sich nicht annähernd in gleichem Maße weiterentwickeln wie die Informations- und Kommunikationstechnologie, die sie mit einer immer größeren Menge an Information versorgt, nicht mehr fähig, diese Umwandlung ohne Unterstützung durch "intelligente Maschinen" durchzuführen.
Auch wenn wir heute noch weit davon entfernt sind, den Traum von einer "intelligenten Maschine" Realität werden zu lassen, wird er doch ungebremst weiter vorangetrieben. Ob dieses Ziel in absehbarer Zeit erreicht wird, ist fraglich; indes sind schon die Zwischenergebnisse auf dem Weg dorthin von umwälzendem Potential. Das Forschungsfeld, welches diesen Traum voranbringt, heißt Künstliche Intelligenz.
Roger Penrose, als Beispiel für einen modernen Kritiker der KI, argumentiert, daß die Vorgänge im menschlichen Gehirn als Vorbild für Intelligenz die heutigen Vorstellungen und Techniken der KI übersteigen. Er meint, daß erst weitere Erkenntnisse in Forschungsfeldern wie beispielsweise Quantenmechanik und Mikrobiologie das Verhalten von Gehirn, Geist und Bewußtsein ausreichend genug verstehen lassen werden. [Penrose 1994]
Trotz aller enttäuschter Hoffnungen, Fehlschläge und Kritik wird weiter auf dem Gebiet der KI geforscht.
Neben dem Wunsch, Systeme zu entwickeln, die uns helfen, der Informationsflut Herr zu werden, der wir uns ausgesetzt sehen, wird die KI-Forschung unter anderem angetrieben von dem Wunsch nach Maschinen, die Menschen bei wichtigen Routineaufgaben assistieren, die schnell komplexe Aufgaben ausführen oder Lösungen für komplexe Probleme finden und als eine Art elektronischer Stellvertreter für uns arbeiten. [Smith, Mamdani 1997, S.264]
Ein grundlegendes Problem der KI ist die Frage, wie Wissen geeignet in Maschinen repräsentiert werden kann und mit welchen Methoden aus diesem Wissen neue Schlüsse gezogen werden können. Zwei Hauptrichtungen versuchen sich an der Lösung dieser Fragestellung: Die symbolische KI geht aus von der These, daß sich relevante Fakten und Abhängigkeiten der realen Welt in eine symbolische Ebene abbilden lassen. Mittels Methoden der mathematischen Logik sei es möglich, in dieser symbolischen Ebene neue Fakten und Abhängigkeiten zu erschließen. Für kleine wohl definierte Ausschnitte aus der Realwelt haben Expertensysteme gezeigt, daß dieser Ansatz von Erfolg beschieden sein kann. Je größer der abzubildende Ausschnitt jedoch wird, je komplexer wird die Aufgabe, da bereits bei der Planung des Systems im Rahmen eines sogenannten Knowledge-Engineerings der komplette Abbildungsvorgang stattfinden muß.
Als zweiter Lösungsansatz fungieren Künstliche Neuronale Netze. Forschung auf diesem Gebiet versucht zu ergründen, wie biologische Systeme funktionieren, in denen das Wissen nicht fest vorgegeben ist, sondern im Laufe der Zeit gelernt wird. Trotz aller Forschung auf dem Gebiet der Künstlichen Neuronalen Netze, kann man dennoch nicht von einem Durchbruch reden.
Unter dem Oberbegriff "Soft computing" werden neue Forschungen wie Fuzzy Logik, Genetische Algorithmen oder Stochastische Programmierung, zusammengefaßt. Mittels dieser Forschungsansätze wird versucht, intelligente Systeme zu schaffen, die Ungenauigkeiten oder Unvollständigkeit sowohl der Daten als auch des Programms tolerieren
Rodney Brooks, der prominenteste Kritiker der symbolischen KI, fordert seit 1985, daß intelligente Maschinen, um die reale Welt wirklich verstehen zu können, mit ihr über Sensoren interagieren und ihr Wissen inkrementell aufbauen müssen. Intelligentes Verhalten sei darüber hinaus auch ohne explizite symbolische Repräsentation und abstrakte Schlußfolgerungen erreichbar. Intelligenz sei vielmehr eine emergente Eigenschaft komplexer Systeme. Auf Basis dieser Forderung hat er mehrere Roboter entwickelt, welche - nach [Woolridge, Jennings 1995, S. 28] - Aufgaben ausführen, die beeindruckend wären, würden sie von Systemen der symbolischen KI ausgeführt. Es ist jedoch, im Gegensatz zu klassischen Systemen, schwierig, das nicht symbolisch beschriebene Verhalten vorherzusagen.
Seit 1984 wird im CYC-Projekt [Guha, Lenat 1994], [Nwana, Woolridge 1997, S. 71] versucht, umfassendes "Weltwissen" zu speichern. Bislang umfaßt die Wissensdatenbank 100.000 generelle Konzepte und 1.000.000 Axiome der menschlichen Wahrnehmungswelt, die per Hand kodiert wurden und Millionen mehr, die das System automatisch daraus abgeleitet hat. Diese immense Wissensdatenbank soll dazu dienen, Maschinen eine Art gesunden Menschenverstand beizubringen, um sie Ihre Umwelt besser erfahren zu lassen und miteinander kommunizieren zu können.
Software Agenten als Multiagenten Systeme ("Multi Agent Systems" (MAS)) bilden gemeinsam mit den Bereichen Verteiltes Problemlösen ("Distributed Problem Solving") und Parallele Künstliche Intelligenz ("Parallel AI") das Forschungsgebiet Verteilte Künstliche Intelligenz (VKI) oder "Distributed AI" (DAI).
Als Argumente für den Einsatz von Systemen mit verteilter KI und Multi Agenten Systemen führen [Nwana, Ndumu 1997, S. 8] an:
- Durch die Kombination vieler Einzelagenten soll ein Mehrwert entstehen, der über die reine Summe der Möglichkeiten der Einzelagenten hinausgeht.
- Das Ausfallrisiko und die Beschränkung der Ressourcen eines zentralen Systems sollen umgangen werden.
- Bestehende Systeme (z.B. Expertensysteme, konventionelle Programme) sollen integriert werden.
- Es sollen einfacher Lösungen gefunden werden für verteilte Probleme, wie beispielsweise Suche in verteilten Information.
Carl Hewitts Concurrent Actor Model ( [Hewitt 1977, S.323ff] nach [Nwana 1996, S. 2]) gilt als Ausgangspunkt der Forschungen zu Software Agenten. Er schlägt ein unabhängiges, interaktives und parallel ablaufendes Objekt vor, welches er als "Actor" bezeichnet. Es hat einen von der Umwelt abgeschirmten Zustand und kann mit anderen Objekten kommunizieren. Ein "Actor"
"is a computational agent which has a mail address and a behavior. Actors communicate by message-passing and carry out their actions concurrently." [Hewitt 1977]
Von diesem Zeitpunkt an beschäftigte sich ein Forschungsgebiet der DAI mit deliberativen Agenten, die ein symbolisches internes Modell zur Wissensrepräsentation[16] 5.1.1.2 verwenden. In diesem Bereich werden bis heute insbesondere Makro-Aspekte wie Interaktion und Kommunikation zwischen Agenten[17] 5.1.7.1 oder Strategien für Koordination, Kooperation und Konfliktlösung behandelt[18] 5.1.3 .
Parallel dazu wurde Forschung und Entwicklung im Bereich der Theorie, Architektur und Sprache von Agenten-Systemen betrieben. In [Woolridge, Jennings 1995] und [Nwana, Woolridge 1997] wird dieser Bereich zusammengefaßt und ab Abschnitt 5.1.5 dargestellt.
Ab circa 1990 begann die Forschung auf dem Gebiet der Agenten sich rapide auszuweiten. Das Konzept, welches zuvor insbesondere unter theoretischen Gesichtspunkten als eher abstrakte Forschungsvorhaben betrieben wurde, breitete sich aus.
Ab 1993 führte die rasante Verbreitung des Internets und des WWW als globales Informationssystem zum Entstehen einer neuen Art von "Agenten", die nochmals zu einer Erweiterung des Agenten-Begriffes führte und zu dessen inflationären Gebrauch beitrug. Kapitel 5.2 zeigt diesen Ansatz auf.
Das zentrale Problem von Multi Agenten Systemen stellt die Koordination der einzelnen Agenten untereinander dar. Die Arbeit der Einzelagenten muß koordiniert werden, um ein globales Ziel zu erreichen, zwischen den unterschiedlichen Fähigkeiten und Wünschen der einzelnen Agenten zu vermitteln und Abhängigkeiten zwischen den Agenten aufzulösen. Ohne Koordination tendieren Systeme mit vielen autonom arbeitenden Einzelagenten zum Chaos.
Koordination beinhaltet die Aufteilung und Verteilung von Aufgaben auf verschiedene Agenten, die Koordination und Kooperation der Agenten untereinander und Konfliktlösungs- oder Verhandlungsstrategien; sie kann auf verschiedene Arten erfolgen: vorgegebene Strukturen, Vertragsnetze, Multi-Agenten Planung.
- Die einfachste Möglichkeit besteht aus einer fest vorgegebenen Struktur ("organisational structuring") des Systems, in der die einzelnen Rollen und Funktionen im Gesamtsystem fest vorgegeben sind. Beispielsweise kann die Gesamtheit der Agenten in "master agents" und "slave agents" unterteilt sein. Die master agents delegieren Aufgaben an die slave agents. Eine andere Art der Strukturierung kann ein sogenanntes "Blackboard" - also eine Art "schwarzes Brett" - sein, das von master agents verwaltet wird und als zentrale Anlaufstelle für die Verteilung von Aufgaben im System dient. Ein Schwachpunkt dieses prinzipiell einfach zu realisierenden Ansatzes ist die Gefahr von Engpässen, die bei einer oder wenigen zentralen Kontrollinstanzen leicht entstehen kann.
- In Vertragsnetzen ("contract nets") gibt es - ähnlich zu dem Ansatz der festen strukturierten Systeme - "manager agents", die eine Aufgabe aufteilen und "contractor agents" suchen, die diese Aufgaben ausführen. Der Unterschied liegt jedoch darin, daß contractor agents rekursiv auch zu manager agents werden können und die ihnen übertragenen Aufgaben weiter aufteilen und verteilen können. Ebenso ist die Struktur des Systems nicht fest vorgegeben. Um eine Aufgabe können mehrere contractor agents konkurrieren, von denen der manager agent den günstigsten auswählt. Der Ansatz der Vertragsnetze bietet viele Vorteile gegenüber der festen Struktur: es kommt insbesondere zu keinen Engpässen, da mehrere Agenten um eine Aufgabe konkurrieren und stark ausgelastet Agenten nicht um die Vergabe der Aufgabe bieten müssen. Es behandelt jedoch keine Konflikte zwischen den einzelnen Agenten und geht davon aus, daß alle Agenten zusammenarbeiten.
- Multiagenten-Planung ("multi-agent planning") bedeutet, daß jeder Agent für sich eine Vorgehensweise zur Durchführung der zentralen Aufgabe plant, die dann jedoch entweder einer zentralen Instanz vorgelegt wird ("centralised multi-agent planning"), um Inkonsistenzen und Konflikte auszuschalten, oder von jedem Agenten selbst mit allen anderen Agenten abgeglichen wird ("distributed multi-agent planning"). Dieser Ansatz setzt eine größere Menge an Information und Kommunikation der Agenten untereinander voraus. Bei einer zentralen Instanz zur Kontrolle der Pläne tritt jedoch das Engpaß-Problem wieder auf.
Insbesondere wenn sich Agenten koordinieren sollen, die sich nicht ausschließlich dem Gemeinwohl verpflichtet fühlen, also antagonistisch handeln, gewinnen Verhandlungstechniken ("Negotiation" [Nwana, Lee, Jennings 1997, S.49ff]) an Bedeutung. Als Verhandlung wird bezeichnet
"[...] the communication process of a group of agents in order to reach a mutually accepted agreement on some matter."
Nach dem spieltheoretischen Verhandlungsansatz ("game theory-based negotiation") werden anhand einer Nutzenfunktion alle möglichen Ausgänge des Verhandlungsprozesses ausgehend von den unterschiedlichen Geboten der beteiligten Verhandlungspartner bewertet. Diese Bewertung muß allen Verhandlungspartnern bekannt sein. Die Verhandlungspartner versuchen, über ein iteratives Verhandlungsprotokoll den für sie größten Nutzen aus der Verhandlung zu ziehen. Agenten, die lügen oder Informationen vorenthalten, um einen größeren Vorteil zu erreichen, stellen eine mögliche Erweiterungen dieses Ansatzes dar. Die Tatsache, daß alle an einer Verhandlung beteiligten Agenten alle Bewertungen kennen müssen, ist der hauptsächliche Kritikpunkt dieses Ansatzes. Darüber hinaus kann sich die Menge der Bewertungen bei umfangreichen Verhandlungen zu einem Problem entwickeln.
Neben diesem Ansatz existieren noch viele weitere Überlegungen für automatische Verhandlungen. Teilweise werden nach [Nwana, Lee, Jennings 1997, S.52f] auch unabhängige Dritte als Vermittler zwischen den Parteien eingeschaltet, um Verhandlungsvorschläge zu unterbreiten. Einen eher pragmatischen Ansatz gehen [Chavez et al. 1997] mit Kasbah, einem "Marktplatz für Agenten", auf dem Agenten mit Produkten handeln. Der wichtigste Parameter, durch den die Verhandlung bestimmt wird, ist der geforderte Preis für ein Produkt, der anhand unterschiedlicher Strategien bis zu einem definierbaren Minimum fällt. Wenn ein Agent bereit ist, den geforderten Preis zu bezahlen, kann der Handel - nach einer Bestätigung durch den Benutzer - stattfinden. Hierbei handelt es sich also um eine Art von Auktion. Auktionen sind eine sehr formalisierte Form der Verhandlung über ein bestimmtes Attribut, in der Regel den Preis, eines Produktes und lassen sich relativ einfach automatisieren.
Traditionelle Techniken des Maschinenlernens ("Machine Learning") sind nach [Green et al. 1997, S. 6] die symbolische und subsymbolisch Klassifikaton ("symbolic and subsymbolic classifiers").
- In der symbolischen Klassifikation werden alle möglichen Zustände des Systems anhand einer endlichen Zahl von Attributen in Klassen unterteilt. Zu einem späteren Zeitpunkt kann dann bei Auftreten genau dieser Attribute mittels eines Entscheidungsbaumes wieder auf die Klasse geschlossen werden: die Situation ist erkannt worden.
- Die subsymbolische Klassifikation verwendet Neuronale Netze und erkennt Muster von Attributen und nicht die Attribute selbst. Überwachte Neuronale Netze ("Supervised Neuronal Networks") werden anhand zuvor bekannter Kategorien trainiert, wobei sukzessiv Fehlschlüsse beseitigt werden. Unüberwachte Neuronale Netze ("unsupervised Neuronal Networks") sind fähig, aufgrund der Muster selbständig unterschiedliche Klassen zu bilden und die Muster in diese einzuordnen.
Ein Nachteil traditioneller Techniken des Maschinenlernens besteht darin, daß - bis auf bei Unüberwachten Neuronalen Netzen - das Lernen vor der Benutzung des Systems erfolgen muß und keine Möglichkeit des selbständigen Lernens während des Betriebes besteht.
Der Ansatz des direkten Lernens aus der Umwelt ("Learning Directly From the Environment" [Green et al. 1997, S. 7]) will eben dieses selbständige Lernen erreichen. Mögliche Verfahren sind Verstärkendes Lernen ("Reinforcement Learning"), Lernen durch Beobachtung ("Learning by Observation") und Lernen durch Anweisungen ("Instructional Learning") [Green et al., S. 8].
- Verstärkendes Lernen beruht auf dem Ansatz, daß anhand einer Funktion aus jedem Zustand eine bestimmte Aktion folgt. Bei konkurrierenden Aktionen, die ausgelöst werden können, wird anhand einer Auswahlstrategie entschieden, welche letztendlich ausgelöst wird. Die Funktion wird anhand eines Lernalgorithmus im Laufe der Zeit automatisch an das Benutzerverhalten angepaßt. Wesentliche Aspekte dieses Ansatzes sind also der Lernalgorithmus und die Auswahlstrategie.
- Lernen durch Beobachtung meint, daß einzelne Agenten durch Beobachtung des Verhaltens erfahrenerer Agenten deren Verhalten imitieren und dadurch lernen, wie man in bestimmten Situationen handelt. Es ist kein aktiver Lehrer nötig; die Agenten lernen und beobachten selbständig.
- Als anderes Extrem ist ein Lernen durch Anweisung vorstellbar, Agenten werden explizit zu einem bestimmten Verhalten instruiert. Dies kann durch den Benutzer selbst, oder aber durch erfahrene Agenten erfolgen.
Einen anderen Weg geht das Fallbasierte Schließen ("Case Based Reasoning" [Green et al. 1997]). Hierbei werden die Benutzer des Systems in Klassen eingeteilt und jeder einzelne Benutzer aufgrund seines Verhaltes einer Klasse zugeordnet. Dieser Klasse sind dann stereotype Verhaltensweisen zugeordnet, die der Agent ausübt. Sobald ein Benutzer einer Klasse zugeordnet ist, kann sein Verhalten das Stereotype der Klasse ändern. Der Vorteil dieses Ansatzes besteht darin, daß sich so die einzelnen Benutzerprofile über einen längeren Zeitraum bilden können, als dies in der Regel bei der Interaktion mit nur einem Benutzer der Fall ist.
Jedoch können auch solch einfache Systeme wie ein Lichtschalter als intentionale Systeme beschreiben werden: Ein Lichtschalter ist ein einfacher, kooperativer Agent, dessen Aufgabe darin besteht, Strom fließen zu lassen, wenn er glaubt, daß wir dies wünschen. Der Weg, um mit ihm zu kommunizieren, ist einfach der Druck auf den Schalter.
Es wird deutlich, daß solch eine Beschreibung für einen Lichtschalter keinen Sinn ergibt. Nützlich sind intentionale Beschreibungen jedoch bei Systemen mit komplexer Funktionalität, die nicht einfach zu durchschauen sind. Hier dient eine intentionale Beschreibung als Werkzeug zur Abstraktion, um das Verhalten komplexer Systeme zu beschreiben, erklären und vorherzusagen. Beispielsweise wird oftmals (teilweise sogar unbewußt) das Verhalten eines Computers auf diese Art beschreiben: Sein Verhalten auf einen Mausklick, die Auswahl eines Menüpunktes, etc.
Intentionale Eigenschaften, die einen Agenten beschreiben, lassen sich nach [Woolridge, Jennings 1995, S. 10] in zwei Kategorien einteilen: das Verhältnis zur Information ("information attitudes"), welches die Informationen des Agenten über seine Umgebung beschreibt, und handlungsbeeinflussende Haltungen ("pro-attitudes"), durch die weiteren Aktionen des Agenten gesteuert werden. Information attitudes sind Glauben und Wissen, als pro-attitudes werden unter anderem Wunsch, Absicht, Verpflichtung, Auswahl bezeichnet.
Intentionale Haltungen erlauben keine semantisch eindeutige Beschreibung mit Mitteln der klassischen formalen Logik (Wie soll beispielsweise "Glauben" innerhalb einer zweiwertigen booleschen Logik formalisiert werden?). Der verbreitetste Ansatz zur formalen Darstellung intentionaler Eigenschaften basiert auf dem "Possible Worlds"-Modell nach [Hintikka 1962], welches hier in Anlehnung an [Woolridge, Jennings 1996, S. 12ff] nur grob skizziert wird. Für einen tieferen Einstieg sei auf dieses Arbeit verwiesen.
Ausgehend von einem bestimmten Zustand eines Systems (der "Welt") werden alle möglichen zukünftigen Zustände beschreiben. Eigenschaften, die in allen möglichen Welten auftauchen, werden als "Überzeugung" angesehen. Diese Art der Darstellung scheint auf den ersten Blick umständlich, es läßt sich jedoch über modale Logik eine praktikable formale Beschreibung aus diesem Modell ableiten.
Ein schwerwiegendes Problem des "Possible World"-Modells beruht darauf, daß nach den Gesetzen der Logik alle logischen Folgerungen aus einer Überzeugung ebenfalls wieder zu Überzeugungen werden, was bei einem System mit endlichen Ressourcen zu unüberwindbaren Schwierigkeiten führt. Dieses "Logical Omniscience-Problem" ist bis heute nicht gelöst und stellt den Ausgangspunkt für weitere Forschungen auf diesem Gebiet dar.

Abbildung 9 - "subsumption architecture" von Rodney Brooks
nach
[Nwana,
Ndumu 1997, S.17]
Ein Hauptproblem reaktiver Agentensysteme ist jedoch die Schwierigkeit, ihr Verhalten vorherzusagen.
Ein Beispiel für einen Software-Agenten, der nach diesem Prinzip arbeitet, ist Softbot [Etzioni, Weld 1994]. Softbot arbeitet in einer UNIX-Systemumgebung und soll den Benutzer bei der Benutzung des Systems und des Netzes unterstützen (Interface Agent). Der Benutzer gibt nur an, was er sucht oder was er erledigen möchte und Softbot benutzt und kombiniert anschließend unterschiedliche Werkzeuge und Sensoren auf verschiedenen Systemebenen miteinander, um dieses Ziel zu erreichen. Werkzeuge sind beispielsweise ftp, telnet, mail und viele weitere UNIX-Kommandos; Als Sensoren fungieren beispielsweise archie, gopher oder netfind. Das global zu erreichende Ziel wird aufgeteilt in mehrere Unterziele, die von verschiedenen Softbot-Modulen angestrebt werden.
Nach [Genesereth, Ketchpel 1994, S. 48] besteht eine Grundvoraussetzung eines solchen Systems in einer gemeinsamen Sprache. Ein Agent soll, ähnlich dem Paradigma der Objektorientierung, über Nachrichten mit andere Agenten kommunizieren können. Im Gegensatz zur objektorientierten Programmierung jedoch, in der Nachrichten von Objekt zu Objekt eine unterschiedliche Bedeutung haben können, sollen Agenten eine einheitliche Sprache mit einer agentenunabhängigen Semantik sprechen.
Ein zweites Problem heterogener Agentensysteme und generell von Multi Agenten Systemen ist die Frage, wie die Kommunikation der Agenten untereinander organisiert werden kann. Soll jeder Agent direkt mit jedem anderen kommunizieren können oder sollte es spezielle Vermittler ("Broker") geben, welche die Kommunikation organisieren. Solche Systeme werden als föderale Systeme ("federated systems") bezeichnet. Gegen die direkte Kommunikation spricht der immense Verwaltungsaufwand, wenn jeder Agent jeden anderen kennen muß, um mit ihm kommunizieren zu können. In offenen, dynamisch erweiterbaren Systemen, ist dies oftmals auch gar nicht möglich. Daher ist der Ansatz über Vermittler, die den Kontakt zwischen den Partnern herstellen, verbreiteter.
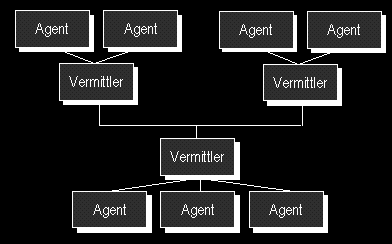
Abbildung 10 - Föderales Agentensystem
nach
[Genesereth,
Ketchpel 1994, S.51]
Agentensysteme müssen jedoch auch selbst in einer Programmiersprache kodiert werden. Einen Einblick in das weite Feld der Agenten-Programmiersprachen gibt abschließend Abschnitt 5.1.7.3.
Der Mehrwert eines Multi Agenten Systems kann jedoch in der Regel nur durch Kommunikation der einzelnen Agenten untereinander erreicht werden. Wenn jeder Agent immer genau wüßte, welche anderen Agenten es noch gibt, welche Bedürfnisse sie haben oder welche Dienste sie anbieten und dazu noch das komplette Wissen aller Agenten hätte, käme ein Multi Agenten Systems ohne eine Kommunikation der Agenten untereinander aus. Dieser Zutand ist jedoch nur in sehr kleinen, trivialen Systemen zu erreichen.
Kommunikation ist sowohl für Systeme notwendig, in denen Agenten kooperieren, um ein gemeinsames Ziel zu erreichen, als auch in Umgebungen, in denen Agenten mit unterschiedlichen Zielen konkurrieren.

Abbildung 11 - Schichtenarchitektur von KQML
aus
[Nwana,
Woolridge 1997, S.63]
Die "Knowlede Query and Manipulation Language" (KQML, [Finin et al. 1994]) stellt einen Ansatz dar, die Sprache, in der Agenten miteinander kommunizieren, zu standardisieren. KQML ist ein Ergebnis des DARPA-Projektes "Knowledge-Sharing Effort" (KSE) [Neches 1994]. Im Rahmen dieses Projektes werden Mechanismen zur Koordination und Informationsübermittlung in verteilten wissensbasierten Systemen untersucht und implementiert.
KQML ist in drei Schichten aufgebaut. In der "content layer" wird die eigentliche Nachricht übermittelt. Über den Inhalt dieser Nachricht sagt KQML nichts aus, so lange sie sich als ASCII-Text repräsentieren läßt. Die "message layer" definiert verschiedene Kategorien von Nachrichten (siehe Tabelle 2) sowie das Protokoll, nach dem diese ausgetauscht werden sollen. Mit Protokoll sind die Regeln gemeint, die für Aufbau und Durchführung der Kommunikationsverbindung von Sender und Empfänger eingehalten werden müssen. Die "communication layer" sorgt für die sichere Übertragung der Nachrichten zwischen den Agenten
Category
|
Message
|
| Basic
informational
|
tell,
deny, untell, cancel
|
| Basic
query
|
evaluate,
reply, ask-if, ask-about, ask-one, ask-all, sorry
|
| Multi-response
query
|
stream-about,
stream-all
|
| Basic
effector
|
achieve,
unachieve
|
| Generator
|
standby,
ready, next, rest, discard, generator
|
| Capability
definition
|
advertise
|
| Notification
|
subscribe,
monitor
|
| Networking
|
register,
unregister, forward, broadcast, pipe, break
|
| Facilitation
|
broker-one,
broker-all, recommend-one, recomment-all, recruit-one, recruit-all
|
Die "Open Agent Architecture" von SRI International nach [Cohen et al. 1994] sieht beispielsweise nur drei Nachrichtent vor: solve, do und post.
Eine Ontologie erweitert die Syntax einer Sprache um die notwendige Semantik.
Ähnlich den Agentensprachen gilt auch für Ontologien, daß alle an einer Kommunikation beteiligten Partner die gleiche Ontologie verwenden müssen, wenn sie sich untereinander verständigen wollen. Für viele begrenzte Wissensgebiete ("Domains") gibt es - meist in Prototypen integrierte - Ontologien. Wie bei proprietären Sprachen kommt es auch hier zu Problemen, wenn die Systeme untereinander kommunizieren müssen. Auch die Erweiterung einer bestehenden Ontologie, um beispielsweise ein neues Wissensgebiet abzudecken, gestaltet sich bei einer impliziten Integration schwierig.
(* (width chip2) (length chip2)))
Das "Knowledge Interchange Format" (KIF) versucht einen anderen Weg einzuschlagen, um das Problem der Semantik von Nachrichten zu lösen. Wie KQML aus dem KSE-Projekt der DARPA entstanden, wird durch KIF ein Meta-Schema für unterschiedliche Wissensbasen beschrieben. Durch ein gemeinsames Meta-Schema werden unterschiedliche Wissensbasen interoperabel und modular einsetzbar.
(ask-if
:language KIF
:ontology Chips
:content (> (* (width chip1) (length chip1))
* (width chip2) (length chip2))))
(reply
:language KIF
:ontology Chips
:in-reply-to Agent1
:content (true))
KIF besteht aus prädikatenlogischen Ausdrücken in first-order Form. Beispielsweise sagt der Satz in Abbildung 12 aus, daß ein Chip größer ist als ein anderer.
Eingebettet in KQML als Teil einer Kommunikation zwischen zwei Agenten, in der Agent 1 zuerst fragt, ob Chip 1 größer als Chip 2 ist und Agent 2 dies anschließend bestätigt, wird daraus die Nachricht in Abbildung 13.
Die Ontologie "Chips", in der im Beispiel festgelegt ist, was die Begriffe "chip1", "chip2", "width" und "length" in diesem speziellen Kontext bedeuten, muß bei beiden Kommunikationspartnern vorhanden sein.
Agent class
|
Language
class
|
Examples
|
Major
reference(s)
| |
| Collaborative
agents
|
Actor
Languages
|
Actors
|
[Agha
1986]
| |
| Agent-oriented
programming languages
|
Agent-0
|
|||
| Placa
|
[Thomas
1995]
| |||
| Interface
Agents, Information Agents,
Mobile Agents
|
Scripting
languages
|
TCL/Tk
|
[Oustershout
1994]
| |
| Safe-TCL,
Safe-Tk[21]
|
[Sunscript
1997]
| |||
| Java
|
[Javasoft
1997]
| |||
| Aglets
|
[Aglets
1997]
| |||
| Telescript/
Odyssey
|
[Genmagic
1997][22]
|
|||
| ]Python
|
[Python
1997]
| |||
| Tacoma
|
[Johansen
1997a]
| |||
| April
|
[McCabe,
Clark 1995]
| |||
| Scheme-48
|
[Kelsey,
Reese 1997]
| |||
| Reactive
agents
|
Reactive
languages
|
RTA/ABLE
|
[Wavish,
Graham 1996]
|
Eine genaue Analyse und Untersuchung der möglichen Programmiersprachen würde den Rahmen dieses Abschnittes sprengen. Tabelle 3 soll daher auch nur einen groben Einblick in das weite Feld der Programmiersprachen für Agentensysteme geben.
Die in der Tabelle angeführten Beispiele umreißen spezielle Sprachen (wie Actors oder Agent-0) zur Konstruktion von Agenten-Systemen und Erweiterungen herkömmlicher Sprachen (Safe-TCL, Safe-Tk als Erweiterung zu TCL/Tk oder Scheme-48 als Erweiterung von Scheme, einem Lisp-Dialekt).
Agenten, die mit ihrer Systemumgebung kommunizieren oder sich gar als Mobile Agenten zwischen Systemen bewegen können, benötigen Schnittstellen zu den Systemen, mit denen sie interagieren oder standardisiserte Laufzeitumgebungen in unterschiedlichen Systemen, zwischen denen sie migrieren können.
Insbesondere für Mobile Agenten wurden an vielen Stellen unterschiedliche Systeme konzipiert. General Magics Telescript [White 1996] war eine der ersten kommerziell verfügbaren Umgebungen für Mobile Agenten, unzählige weitere Architekturansätze existieren, beispielsweise MIME-Agenten mit HTTP[24] als Transportprotokoll [Lingnau, Drobnik, Dömel 1995], Concordia [Mitsubishi 1997], MOLE [Straßer, Baumann, Hohl 1996] (die beiden letzten Architekturen setzen Java als grundlegende Programmiersprache ein).
Durch die weite Verbreitung, den die Programmiersprache Java für verteilte Anwendungen erlangt hat, ist es nicht verwunderlich, daß in zunehmendem Maße auf Java-basierte Architekturen für Mobile Agenten an Bedeutung gewinnen. Für den Erfolg Mobiler Agenten ist eine Interoperabilität zwischen den Systemen verschiedener Hersteller unabdingbar. Die OMG versucht, zusammen mit verschiedenen Partnern wie GMD Fokus, General Magic und IBM, einen Standard für Mobile Agenten zu etablieren (MAF; "Mobile Agent Facility" [MAF 1997]).
Als Abschluß dieses Abschnittes über die Programmierung von Agenten werden zwei Systeme näher vorgestellt: Aglets als Beispiel für Mobile Agenten und das Agent Building Environment (ABE) als Beispiel für ein Architekturbeispiel eines lokalen Agenten.
- Einfachheit und Erweiterbarkeit: Für Java Programmierer soll die Aglet Entwicklung möglichst einfach sein.
- Platformunabhängigkeit: Aglets sollen auf allen Hosts lauffähig sein, die die J-AAPI unterstützen.
- Industriestandard: Die J-AAPI soll ein Industriestandard werden.
- Sicherheit: Vertrauensunwürdige Aglets sollen nicht zum Sicherheitsrisiko für Hosts werden können.
Zur Kommunikation der Aglets untereinander und ihrer Übertragung dient das Agent Transfer Protocol ("ATP" [Lange, Aridor 1997]). ATP definiert die Syntax zur Benennung und Identifikation von Agenten im Internet sowie ein Übertragungsprotokoll für Agenten von Host zu Host.
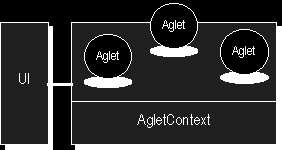
Abbildung 14 - Der AgletContext
nach
[Lange,
Oshima 1997][25]
- Aglet: Ein Aglet ist ein Java Objekt, welches sich zwischen Hosts im Internet bewegen kann.
- Context: Das Context-Objekt dient den Aglets als Ausführungsumgebung in den zu besuchenden Hosts. Der Context stellt Methoden zur Verfügung, um mit anderen Aglets, dem Host oder dem Benutzer (User Interface "UI") zu kommunizieren und schützt den Host vor direkten Zugriffen der Aglets.
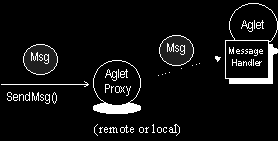
Abbildung 15 - Aglet Messages und Proxies
nach
[Lange,
Oshima 1997]
- Messages ("Nachrichten"): Nachrichten, die Aglets austauschen, sind ebenfalls Objekte. Die Nachrichten können synchron oder asynchron übermittelt werden. Als Empfänger einer Nachricht fungiert immer der stationäre Proxy eines Aglets, der die Nachricht an da Aglet weiterreicht. Ein Aglet muß einen Message Handler, das ist eine spezielle Methode, die beim Eingehen der Nachricht aufgerufen wird, implementieren, die vom Proxy aktiviert wird.
- Itinerary ("Reiseroute"): Das Itinerary-Objekts eines Aglets legt dessen Reiseweg über mehrere Hosts fest.
Eine aktuelle Studie der Intelligent Agent Group am Trinity College Dublin kommt nach einem Vergleich verschiedener Systme für Mobiler Agenten zum Schluß:
"Aglets are possibly the most applicable mobile agent technology at the present moment in time."
Aglets und die Aglet Workbench sind frei verfügbar.
- "Adapters" sind die Sensoren des Agenten, mit denen er seine Anwendungsumgebung ("Application Objects") wahrnimmt und die Werkzeuge, mit denen er sie verändern kann. Jeder Adapter ist nur für genau einen Umgebungsaspekt zuständig. Adapters können passiv die Umgebung beobachten und den Agenten informieren, sobald ein bestimmtes Ereignis eintritt. In diesem Fall wird eine KIF-Nachricht erzeugt und der Engine übermittelt. Adapters können aber auch von der Engine beauftragt werden, eine bestimmte Information einzuholen oder Aktionen auszuführen, die Veränderungen in der Umgebung bewirken. Mögliche Adapter sind ein Timer, der in regelmäßigen Abständen ein Zeitsignal sendet, ein File Adapter, der auf Veränderungen von lokalen Daten reagiert oder diese verändern kann oder ein WWW-Adapter, der WWW Seiten beobachten und erzeugen kann.
- "Engines" (Maschinen) sind die zentralen Steuerelemente des Agenten. So wie das menschliche Gehirn unterschiedliche Zentren für beispielsweise Sprache oder Gedächtnis aufweist, kann es auch in einem Agenten mehrere - auch hybride - Engines für unterschiedliche Aufgabenfelder geben. Eine mögliche Engine ist beispielsweise eine einfache Inferenzmaschine ("Inference"), die auf Grundlage einfacher Regeln Adapter zur Beobachtung und Ausführung nutzt. Andere Engines könnten aus beobachteten Fakten neue Fakten schließen ("Analyser") oder aber Lernmechanismen ("Monitor") bieten.
- Mit "Knowledge" (Wissen) werden einzelne Module bezeichnet, in denen das Wissen, welches unterschiedliche Engines benötigen oder produzieren, abgelegt werden kann. Verschiedene Engines können unterschiedliche Formen der Wissensrepräsentation voraussetzen, so daß es auch verschiedene Module zur Speicherung von Faktenwissen, Regeln etc. geben kann. Alle möglichen Techniken der Wissensrepräsentation, wie Entscheidungsbäume oder Neuronale Netze, sind möglich.
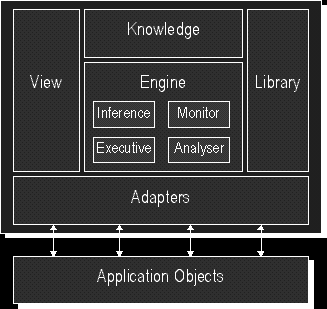
Abbildung 16 - Architektur des ABE
aus
[IBM
1997b]
- "Views" (Sichten) stellen die Schnittstelle zwischen dem Agenten und dem Benutzer dar. Auch in einem adaptiven Agentensystem, in dem der Agent durch Beobachtung des Benutzerverhaltens lernt, muß es für den Benutzer eine Möglichkeit geben, direkt mit dem Agenten zu interagieren, beispielsweise um falsch gelerntes Verhalten wieder zu eliminieren. Außerdem muß der Agent die Möglichkeit haben, von sich aus Rückfragen an den Benutzer zu stellen, und der Benutzer muß direkte Kommandos an den Agenten abgeben können..
Die einzelnen Module sind voneinander unabhängig und können im bisherigen Entwicklungsstadium der ABE in C++ oder Java entwickelt werden. Das ABE ist ebenfalls frei verfügbar.
Um diesem Problem zu begegnen, wurden Suchmaschinen entwickelt, die den Benutzern beim Auffinden von relevanten Informationen behilflich sein sollen.
Solche Suchmaschinen gibt es heute in verschiedensten Ausführungen, die sich hauptsächlich durch die Art und Weise unterscheiden, in der sie Meta-Informationen über das WWW sammeln. Es gibt Suchmaschinen, die aktiv das Netz durchsuchen (sogenannte Spider, Wanderer, Crawler, Bots[27]). Teilweise verlangen sie, daß auf Seiten der Informationsanbieter eine Indexierung vorgenommen wird (z.B. [Aliweb 1997]), größtenteils jedoch indexieren sie die WWW-Seiten selbständig (z.B. [AltaVista 1997] oder [Webcrawler 1997]). Sie fordern die WWW-Seiten mittels des Standardprotokolls HTTP ("Hypertext Transfer Protocol") an, indexieren die enthaltenen Informationen und legen die Meta-Informationen über die abgesuchten WWW-Seiten dann in einer zentralen Datenbank ab.
In dieser Datenbank können Benutzer der Suchmaschine dann nach Stichworten suchen. Crawler folgen in der Regel allen Links, die sie auf besuchten Seiten finden, und indexieren auch die Folgeseiten[28]. In der Liste aktiver Robots [Koster 1997] sind über 130 solcher Crawler angeführt.
Eine andere Art von Suchmaschinen stellen Verzeichnisse, Indexe oder Listen dar (Yahoo, Web.de). Hier werden WWW-Seiten thematisch sortiert. Oftmals gibt es keine, oder nur eine oberflächliche Indexierung der WWW-Seiten, die vom Informationsanbieter in das Verzeichnis eingetragen werden lassen müssen.
Auf Dauer können jedoch auch Suchmaschinen das Problem des Informationsüberangebotes im WWW nicht lösen. Welchen Nutzen bringt dem Benutzer schon eine Liste von 6000 Treffern? Klassische Suchmaschinen versuchen, dieses Problem durch elaborierte Retrievalsprachen mit Boolscher Logik und mannigfaltigen Suchmöglichkeiten zu lösen, die aber die Benutzung in aller Regel stark kompliziert[29].
Weitere Probleme von Suchmaschinen sind deren Erreichbarkeit (Es kommt vor, daß Suchmaschinen wegen zu vieler Netzzugriffe überlastet sind), die Gültigkeit der Treffer (Oftmals gibt es die WWW-Seiten, auf die verwiesen wird, schon gar nicht mehr) und eine geringe Relevanz der Treffer (Ausgelöst durch zu ungenaue Indexierung und Abfragemöglichkeiten).
"The maze of pages and hyperlinks that comprise the Web are the very bottom of the chain. The WebCrawlers and Alta Vistas of the world are information herbivores; they graze on Web pages and regurgitate them as searchable indices. Today, most Web users feed near the bottom of the information food chain, but the time is ripe to move up. Since 1991, we have been building information carnivores, which intelligently hunt and feast on herbivores [...] on the Web"
Mit dem MetaCrawler [Shakes, Langheinrich, Etzioni 1997] und Ahoy! [Selberg, Etzioni 1997] hat Etzioni bewiesen, daß seine Idee intelligenter, nach Informationen jagender Fleischfresser ("carnivores"), die jedoch nicht selbst den Informationsdschungel durchforsten, sondern schwerfällige, behäbige Pflanzenfresser ("herbivores") jagen, auch in der Praxis umsetzbar ist.
Der MetaCrawler ist eine Suchmaschine, die nicht selbst das WWW "abgrast", um in Etzionis Bild zu bleiben, sondern sich (parallel) der Datenbanken vieler anderer Crawler bedient, Mehrfachtreffer aus den Suchergebnissen entfernt und dem Benutzer eine aggregierte Trefferliste anbietet.
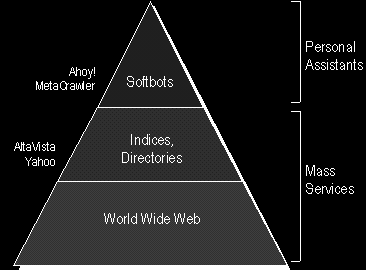
Abbildung 17 - Informations-Nahrungskette im Internet
aus
[Etzioni
1996]
Das Benutzen von Werkzeugen ist für Etzioni ein Kennzeichen von Intelligenz. [Etzioni 1996]. Er nennt seine Werkzeuge "Softbots".
Diese beiden genannten Meta-Crawler sollen nur als Beispiele für eine ganze Klasse von nach diesem Prinzip arbeitenden Programmen im WWW dienen. Andere Beispiele sind MetaGer, ein Meta-Crawler für deutsche Suchsysteme [Sander-Beuermann, Schomburg 1997], oder der BargainFinder, der verschiedene CD-Händler nach einer CD absucht [Andersen 1995] und dem Benutzer einen einfachen Preisvergleich erlaubt.
Ein großes Problem für die Informationssuche im WWW stellen dynamisch erzeugte Informationsangebote dar. Über ein interaktives Formular kann der Benutzer eine Datenbankabfrage starten, deren Ergebnis dann als WWW-Seite präsentiert wird. Hierbei müssen klassische Suchmaschinen versagen, weil sie nicht wissen, wie und womit sie das Formular ausfüllen müssen, um an die relevanten Informationen zu gelangen. Ahoy! und MetaCrawler bedienen sich zwar ebenfalls solcher formular-basierter Abfragesysteme, jedoch sind bei ihnen das Wissen über die Bedienung der Schnittstellen zu den Suchmaschinen fest kodiert.
Fido durchsucht nicht die Angebote im WWW. Seine Produktdatenbank wird von den Anbietern selbst gefüllt. In dieser Datenbank kann der Benutzer dann nach bestimmten Produkten suchen. Das Problem dieses Ansatzes ist offensichtlich: Jede Änderung in Preis oder Sortiment eines Anbieters muß auch in Fidos Datenbank geändert werden: ein immenser Aufwand. Mehrere Versuche, über Fido aktuelle Produkte zu finden, hinterließen den Eindruck, daß Continuum Software, die Betreiber von Fido, dieses Projekt aufgegeben zu haben scheinen.
Der Shopbot, ebenfalls ein Vertreter der Softbots von Etzioni, versucht das Problem "intelligenter" zu lösen: Er ist - zumindest der Beschreibung nach - fähig, selbständig zu lernen, wie man über Datenbankabfragen an Preisinformationen verschiedener Anbieter gelangt. Einzig die Adressen der Anbieter sowie einige Informationen über die Produktkategorie genügen ihm, um durch eine Art "Learning by doing" in einem interaktiven Prozeß zu ermitteln, wie er diese Informationen bei unterschiedlichen Anbietern erhalten kann. Dieser Ansatz scheint vielversprechender zu sein als Fido.
Viele Kleinanzeigen großer - leider bislang nur amerikanischer - Zeitungen kann man mit [Adhound 1997] mit nur einer Anfrage durchsuchen. Das Profil läßt sich abspeichern und automatisch wiederholt ausführen. Das Besonderer an Adhound ist die Tatsache, daß die Betreiber die Daten in einer eigenen Datenbank pflegen, ähnlich dem ShopFido-Ansatz aus dem vorherigen Abschnitt, es damit aber offensichtlich ernster nehmen und mehr Erfolg haben.
Eine spezielle Art von Informationsfiltern sind Angebote wie [Infomarket 1997] oder [Infowizard 1997]. Diese beiden Informationsfilter bieten Fachinformationen aus bestimmten (technischen) Gebieten, die sie aus unterschiedlichen Quellen und gegen Gebühr anbieten. Infowizard erlaubt das Anlegen und automatische Ausführen von Suchprofilen.
Über eine Art "Social filtering" versuchen Agenten wie [Firefly 1997] oder [Morse 1997] aus den Lieblingsfilmen oder der Lieblingsmusik eines Benutzers durch Vergleich mit den Präferenzen anderer Benutzer neue Filme oder Musikgruppen zu ermitteln, die dem eigenen Geschmack entsprechen könnten. Firefly erweitert das Konzept dahingehend, daß man Personen finden kann, die den gleichen Geschmack haben wie man selbst.
Informationsfilter versuchen, dem Benutzer automatisch nur relevante Informationen zu liefern, ohne daß er lange danach suchen muß. Die Integration unterschiedlicher Informationsquellen ist ein weiterer Vorteil, den Informationsfilter bieten können. Den größten Schwachpunkt bestehender Informationsfilter stellt die Methode dar, mit der das Benutzerprofil erstellt wird. Anstelle vom Benutzer zu fordern, seine Wünsche explizit anzugeben, wäre ein indirektes Verfahren wünschenswert, daß aus den Handlungen des Benutzers (z.B. Verweildauer auf einzelnen WWW-Seiten, Art der verfolgten Links) selbständig ein Benutzerprofil erstellt. [OpenSesame 1997] ist ein Beispiel für ein derartiges System
[Pointcast 1997] als der bekannteste Vertreter dieser Technologie erlaubt beispielsweise, in regelmäßigen Abständen Nachrichten aus Quellen wie Reuters, Time Warner, Boston Globe und Los Angeles Times auf den heimischen Rechner zu übertragen, die dann in Form eines Bildschirmschoners oder eines Nachrichtentickers abgespielt werden.
Bei [Freeloader 1997] kann der Benutzer sich zuvor ausgewählte WWW-Seiten auf den heimischen Rechner übertragen lassen.
Der Vorteil des Push-Ansatzes liegt darin, daß gegenüber den Informationsfiltern keine ständige Internetzugang nötig ist. Die Informationen werden auf einen Schlag übertragen und können später in aller Ruhe auf dem lokalen Rechner gesichtet werden. Diese Übertragung kann auch automatisch zu Zeiten geringer Netzbelastung oder Übertragungskosten durchgeführt werden.
Ein Nachteil dieses Ansatzes besteht darin, ein weiteres lokales Programm installieren zu müssen. Durch Absichtserklärungen von Microsoft und Netscape - der beiden führenden Unternehmen im WWW-Browser-Markt -, diese Art der Technologie in ihre neuen WWW-Browsern zu integrieren, wird dieser Nachteil jedoch an Bedeutung verlieren.
Der bereits in Abschnitt 5.2.2 erwähnte BargainFinder [Andersen 1995] war einer der ersten im WWW verfügbaren Shopping Agenten. Nach Eingabe von Titel und Interpret einer CD fragt er bei verschiedenen Händlern nach und liefert die unterschiedlichen Preise für das Produkt. Nach kurzer Zeit wurden die konzeptionellen, technischen und organisatorischen Probleme, mit denen BargainFinder zu kämpfen hat und an denen er auch schließlich scheiterte, offensichtlich: Viele der Händler waren nicht daran interessiert, den Kunden ein solches Werkzeug zu bieten.
Die berechtigten Argumente gegen BargainFinder sind, daß der reine Produktpreis zu wenig über die unterschiedlichen Preisgestaltungen der Händler aussagt. Beispielsweise könnte ein Händler zwar einen günstigeren Preis für eine CD verlangen, durch zusätzliche Bearbeitungskosten, Versand- und Verpackungsmaterial aber letztendlich doch teurer werden als ein anderer Anbieter. BargainFinder kann derartige Untersuchungen nicht durchführen.
Auch werden viele Mehrwerte, die Händler anbieten, wie Kritiken, Proben und Empfehlungen bei einem Shopping Agenten wie BargainFinder nicht berücksichtigt.
Mittlerweile blockieren viele der Händler den Zugriff von BargainFinder, was technisch sehr einfach zu realisieren ist, da BargainFinder immer von einer festen und bekannten Adresse im WWW aus die Anbieter abfragt und darauf angewiesen ist, die genaue Struktur der Abfrageformulare der Anbieter zu kennen.
Neben einigen Systemen, die entweder mit ähnlichen Problemen zu kämpfen haben wie BargainFinder (z.B. [Bargainbot 1997], [Check it out! 1997] und [MX Bookfinder] oder aber eher experimentellen Charakter haben (Shopbot (siehe Abschnitt 5.2.3)), stellt [Jango 1997] die aktuellste Entwicklung auf dem Gebiet der Shopping Agenten dar.
Jango[30], eine kommerzielle Weiterentwicklung von Shopbot, muß vom Benutzer lokal installiert werden und arbeitet vom lokalen Rechner aus, was es für den Anbieter unmöglich macht, den Zugang auf eine ähnlich einfache Weise zu sperren wie dies bei BargainFinder möglich war.
Netbot, der Anbieter von Jango, hat ihn auf verschiedenen Gebieten (Bücher, Wein, Computer, CDs, etc.) "trainiert", das bedeutet mit Informationen über Anbieter, aber auch über dritte Informationsanbieter zu dem jeweiligen Produkt, versehen. Eine Suchanfrage wird, versehen mit den jeweils passenden Argumenten wie Interpret und Titel einer CD, an die bekannten Händler geschickt und ausgewertet. Gleichzeitig wird in Suchmaschinen und Newsgroups nach dem Produkt gesucht, so daß nach ein bis zwei Minuten eine Reihe von Links zu Anbietern und Informationen über das Produkt bereitstehen. Abbildung 18 zeigt ein exemplarisches Suchergebnis. Im linken Bereich sieht man die verschiedenen Trefferklassen, die angeboten werden: Neben den verschiedenen Preisen werden Verweise auf Hersteller, Kritiken und unterschiedliche andere Informationen zum gesuchten Produkt angeboten.
Nach der Auswahl eines Anbieters wird das Bestellformular automatisch mit den Kundeninformationen gefüllt und man muß es in einfachsten Falle nur noch abschicken.
Die Produktkategorien, in denen Jango eingesetzt werden kann, sowie die einzelnen Anbieter werden von Netbot ständig erweitert und aktualisiert und können beim Start von Jango autmatisch aktualisiert werden.
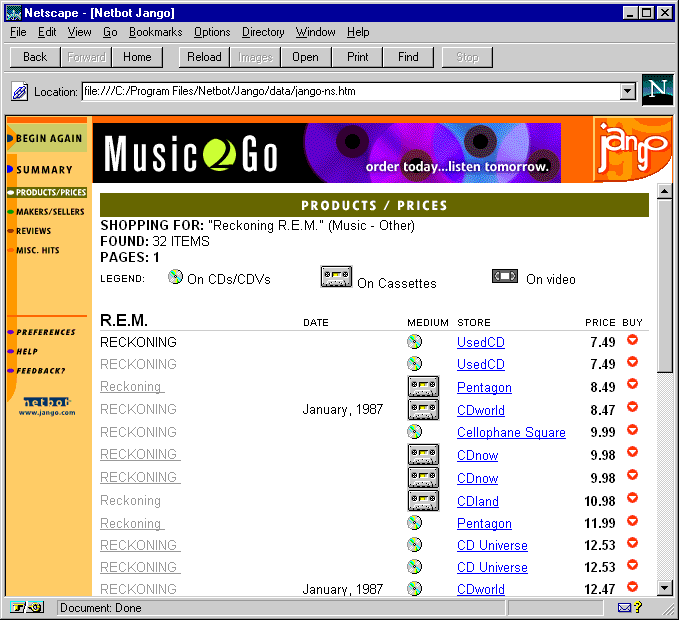
Abbildung 18 - Jango auf der Suche nach CDs
Jango arbeitet nicht in allen Bereichen gleich effektiv. Bei CDs und Büchern genügen wenige Suchkriterien, um relevante Ergebnisse zu liefern; in Bereichen wie beispielsweise dem Computerhandel, läßt sich Jango ebenso wie ein menschlicher Käufer, durch die Unmenge von Variationsmöglichkeiten verwirren, wie in [Economist 1997b] bemerkt wird. Im gleichen Artikel wird eine mögliche Konsequenz beschreiben, wenn sich Shopping Agents durchsetzen: Der unerbittliche Preiskampf könnte dazu führen, daß alle Preise sich immer weiter einem gemeinsamen Minimum angleichen, so daß Shopping Agents sich auf lange Sicht selbst unnötig machen.
Diese Aussicht ist sicherlich noch ferne Zukunftsmusik, wenn Jango jedoch halten kann, was Netbot verspricht, so könnte dieses Produkt den Durchbruch im Bereich der Shopping Agenten bedeuten. Dann müßten die Anbieter von Produkten sich von der Vorstellung lösen, Kunden durch aufwendig gestaltete WWW-Seiten oder herkömmliche Werbung gewinnen zu wollen; andere Fragen, wie beispielsweise die Frage, ob Shopping Agenten die eigene Produktpalette einfach. vollständig und korrekt erfassen können, gewinnen an Bedeutung.
Diese ersten praktischen Ansätze von Shopping Agents, insbesondere Jango, führen in letzter Konsequenz zu der Version eines Elektronischen Marktplatzes, auf dem Agenten in der Rolle von Anbietern mit Agenten in der Rolle von potentiellen Kunden um Produkte und ihre Preise verhandeln. Im Gegensatz zu vielen theoretischen Überlegungen und prototypischen experimentellen Implementierungen auf diesem Gebiet, stellen die existierenden Shopping Agents eine Annäherungen von der Implementierungsseite des Problems dar. Eine Art bottom-up Ansatz in den Grenzne des heute technisch Machbaren im Gegensatz zu der top-down Einführung eines "neuen" Systems.
Eine andere Klasse von Agenten für das WWW beobachtet für den Benutzer laufend bestimmte Informationsseiten und teilt ihm Änderungen mit. (z.B. [Netmind 1997]).
Daneben gibt es noch Agenten, die in spezielle WWW-Angebote integriert sind und für dem Benutzer bestimmte Aufgaben abnehmen, wie beispielsweise Eyes von [Amazon 1997]. Eyes bietet die Möglichkeit, sich über Änderungen im Produktkatalog des Buchhändlers Amazon informieren zu lassen. Dazu kann man eine Suchanfrage nach unterschiedlichen Kriterien im Produktkatalog abspeichern, die vom System dann regelmäßig ausgeführt wird.
Die Entwicklung in diesem Bereich schreitet rasch voran, jedoch sind zwei wichtige Punkte der Definition Intelligenter Agenten aus Kapitel 4 noch lange nicht erfüllt: Zum einen sind die Agenten weit davon entfernt, wirklich "intelligent" zu sein, ja sie erfüllen teilweise nicht einmal im Ansatz die Kriterien, die in dieser Arbeit an Intelligente Agenten gestellt werden. Zum zweiten ist das Vertrauen, daß Benutzer in diese Agenten setzen, noch nicht sehr ausgeprägt.
Gerade der zweite Punkt kann sicherlich durch die weite Verbreitung von Agenten im WWW und die Einsicht in die Notwendigkeit auf Seiten der Benutzer auf lange Sicht überwunden werden, wenn die Technik verantwortungsvoll eingesetzt und entwickelt wird.
In dem Maße, in dem die zu bewältigenden Aufgaben komplexer werden, wird auch der Einsatz von Methoden der Künstlichen Intelligenz, wie sie in Kapitel 5.1 vorgestellt werden, immer stärker zum Motor neuer, besserer Intelligenter Agenten im WWW werden.
[15]: Der Sieg des Schachcomputers Deep Blue über den amtierenden Schachweltmeister Garry Kasparow am 11. Mai 1997 hat großes Aufsehen erregt und die Welt der Erfüllung von Simons Prophezeiung einen Schritt näher gebracht [IBM 1997a].
[16]: siehe Abschnitt
[17]: siehe Abschnitt
[18]: eine kurze Einführung in dieses Gebiet folgt in Abschnitt
[19]: siehe Abschnitt
[20] : Die angesprochene Vermittlerfunktion findet sich auch im Umfeld verteilter Objekte wieder. Archtiekturen wie beispielsweise CORBA ("Common Object Request Broker Architecture" [OMG 1997]; <http://www.omg.org/corba/corbiiop.htm>) setzen einen "Object Request Broker" (ORB) ein, um die Kommunikation zwischen netzweit verteilten Objekten zu realisieren. CORBA ist ein Standard der OMG ("Object Management Group", [OMG 1997]).
[21]: Die SUN Microsystems Inc. entwickelt ab 1995 TCL/Tk ("Tool Command Language" und deren grafische Benutzerschnittstelle "Toolkit") als eigenes Produkt unter der Bezeichnung SunScript und hat die Konzepte von Safe-TCL in die aktuelle Version 7.5 integriert.
[22]: General Magic entwickelt als technischer Vorreiter auf dem Gebiet Mobiler Agenten ab 1990 Systeme für Mobile Agenten. Nachdem ihr proprietäres System Telescript ([White 1996]) sich auf dem Markt nicht durchsetzen konnte, setzt General Magic ab Februar 1997 mit ihrem neuesten Produkt Odyssey auf Java <http://www.genmagic.com/agents/odyssey.html>.
[23]: <http://www.cs.umbc.edu/agents/technology/asl.shtml>
[24]: HTTP ("Hypertext Transfer Protocol") ist der Standard nach dem im WWW Informationsseiten übermittelt werden.
[25] : <http://www.trl.ibm.co.jp/aglets/aglet-book/context.html>
[26] : <[26]http://www.trl.ibm.co.jp/aglets/aglet-book/message.html>
[27]: Im Rahmen dieser Arbeit werden alle diese Bezeichnungen, sofern sie im Kontext von Suchmaschinen im WWW gebraucht werden, synonym verwendet.
[28]: In [Cheong 1996] ist die Funktionsweise einiger solcher Suchmaschinen ausführlicher beschrieben.
[29]: LiveTopics von AltaVista sei hier als fortschrittlichster Ansatz aufgezeigt, dem Benutzer ein Relevance Feedback für umfängliche Trefferlisten zu erlauben. Auf Basis einer Relevanzuntersuchung werden die häufigsten Indexterme der gefundenen Dokumente grafisch dargestellt. Der Benutzer kann durch einfaches Auswählen einzelner Indexterme seine Suchanfrage einschränken.
[30]: Der Name Jango wurde gewählt, "because it means absolutely nothing in seven critical languages". Keith Zentner, Marketingleier Netbot, in [Andrews 1997].